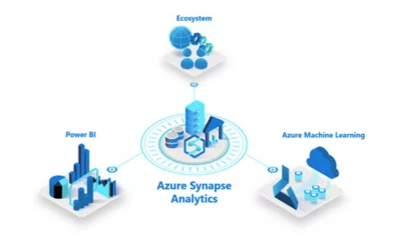
在數字經濟浪潮奔涌的今天,數據已被視為與土地、勞動力、資本、技術并列的新型生產要素。它如同水一般,從各個源頭涓涓匯入,形態各異(結構化、半結構化、非結構化),流速不一(實時流、批量)。傳統的數據倉庫如同精心規劃的水庫和管道系統,雖然能提供高質量、標準化的“飲用水”,但其嚴格的架構和預處理要求,在面對海量、多樣、高速的“數據洪水”時,往往顯得力不從心,甚至成為創新的瓶頸。
于是,“數據湖”這一概念應運而生,它旨在構建一個能夠海納百川、原樣存儲所有原始數據的集中式存儲庫。數據湖的核心思想是“先存儲,后治理”,允許數據以最原始的形態自由流入,為后續的探索、分析、機器學習和高級數據服務保留了最大的靈活性與可能性。早期粗放的數據湖建設也帶來了新的挑戰——“數據沼澤”,即數據無序堆積、質量堪憂、難以查找和使用,這恰恰暴露了缺乏有效治理的弊端。
因此,現代數據湖的演進,正與數據治理深度融合,催生出一種全新的治理范式。這種新范式并非回歸數據倉庫的嚴格預定義,而是倡導一種更具適應性和智能化的治理方式:
- 治理左移與自動化:治理策略不再僅僅是事后補救。通過在數據入湖的入口部署元數據自動捕獲、數據分類、敏感信息識別和基礎質量檢查,從源頭開始建立秩序。自動化的數據血緣追蹤能夠清晰描繪數據的來龍去脈,為理解數據、評估影響奠定基礎。
- 元數據驅動的治理:元數據是數據湖的“導航圖”和“說明書”。強大的元數據管理不僅記錄數據的結構,更記錄其業務含義、血緣關系、訪問權限、質量分數和使用熱度。這使得數據消費者能夠像在圖書館查閱目錄一樣,快速發現和理解所需數據,從而將“湖”變為“知識庫”。
- 彈性Schema與數據質量:支持Schema-on-Read(讀時模式),允許在讀取和分析數據時再應用結構,這提供了靈活性。但通過定義和維護數據質量規則(如完整性、一致性、有效性校驗),并持續監控,確保湖中數據的可信度。治理的目標是保障數據的“可用性”和“可靠性”,而非僵化的“一致性”。
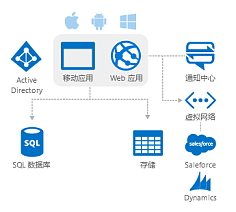
- 安全、合規與隱私的嵌入式保障:數據湖作為集中存儲點,必須內置精細化的訪問控制、數據加密、審計日志和脫敏能力。特別是隨著隱私法規(如GDPR、個保法)的完善,治理范式必須包含數據生命周期管理、合規性檢查和個人信息保護機制,確保數據在自由流動的同時安全可控。
當數據治理的基石被夯實,數據湖的真正價值——賦能數據服務——才得以全面釋放。治理良好的數據湖為構建敏捷、多樣的數據服務提供了肥沃的土壤:
- 統一數據服務層:基于治理后的可信數據,可以構建統一的API服務層,將原始數據封裝成易用的數據產品(如客戶畫像API、實時指標服務),供業務系統、數據分析師和應用程序直接消費,實現數據的資產化和價值閉環。
- 自助式分析與AI/ML賦能:業務用戶和分析師可以在受控的安全環境下,直接訪問治理過的數據湖,進行自助式的數據探索和可視化分析。豐富、原始的底層數據是訓練機器學習模型的絕佳燃料,驅動預測性分析和智能化應用。
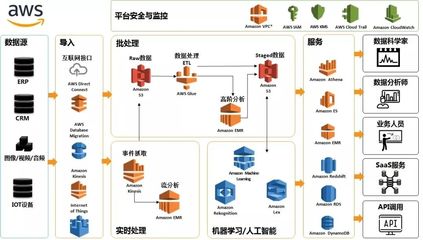
- 支持多模態計算引擎:治理框架確保數據可被統一訪問,而底層則可以對接SQL查詢引擎(如Presto/Trino)、批處理引擎(如Spark)、流處理引擎(如Flink)等多種計算框架,滿足從離線報表到實時洞察的全場景需求。
數據湖并非數據治理的“法外之地”,恰恰相反,它正推動數據治理從以管控為中心的傳統模式,轉向以賦能和價值實現為中心的新范式。這一范式強調在保持數據靈活性與原始保真度的通過自動化、智能化的手段嵌入治理,最終目標是將浩瀚的“數據之水”轉化為可便捷取用、安全可靠、驅動創新的“數據服務”。數據如水,治理如渠,服務如泉,唯有渠清有序,方能泉涌不息,真正釋放數據的磅礴力量。